
A Hashtable is a data structure that stores key-value pairs, allowing for efficient access and retrieval of values based on their associated keys.
In a Hashtable, the key is used to calculate an index into an array of buckets, which contain the values.
Since the value being searched for and the index of the table are the same, it is possible to directly access the location where the value is stored without having to search through the table. Therefore, the time complexity is O(1).Similarly, actions such as inserting, modifying, and deleting values in the table can also be resolved in O(1) time complexity as long as the location of the value is known. The reason why algorithms for searching, inserting, modifying, and deleting values in such simple data structures usually take up time is often quite similar.
Advantages of Hashtable:
- Fast access: Hashtable allows for fast access to values based on their keys.
- Efficient storage: Hashtable typically uses less memory than other data structures, such as linked lists or arrays, for storing large amounts of data.
-
Flexibility: Hashtable is a dynamic data structure that can grow or shrink as needed.
Disadvantages of Hashtable:
- Hash collisions: If two keys map to the same index in the array, a hash collision occurs, which can reduce the efficiency of the Hashtable.
- No ordering: Hashtable does not maintain the order of the inserted elements, making it unsuitable for some use cases.
- Additional memory: Hashtable requires additional memory to store the array of buckets.
Use Cases:
- Caching: Hashtable can be used for caching frequently accessed data to improve performance.
- Dictionary: Hashtable can be used as a dictionary, with words as keys and definitions as values.
- Counting occurrences: Hashtable can be used to count the occurrences of items in a dataset.
Collision:
When a different value is inputted into the hash function, but the
same value pops out, it is called a collision.

Hash tables, which are made up of keys and values, are a data structure that exhibits excellent performance. However, they cannot be used in all cases due to hash collisions.
Hash collisions occur when different keys result in the same hash code through a hash function.
In hash tables, the problem caused by collisions is solved by two methods: separate chaining and open addressing.
Separate Chaining:
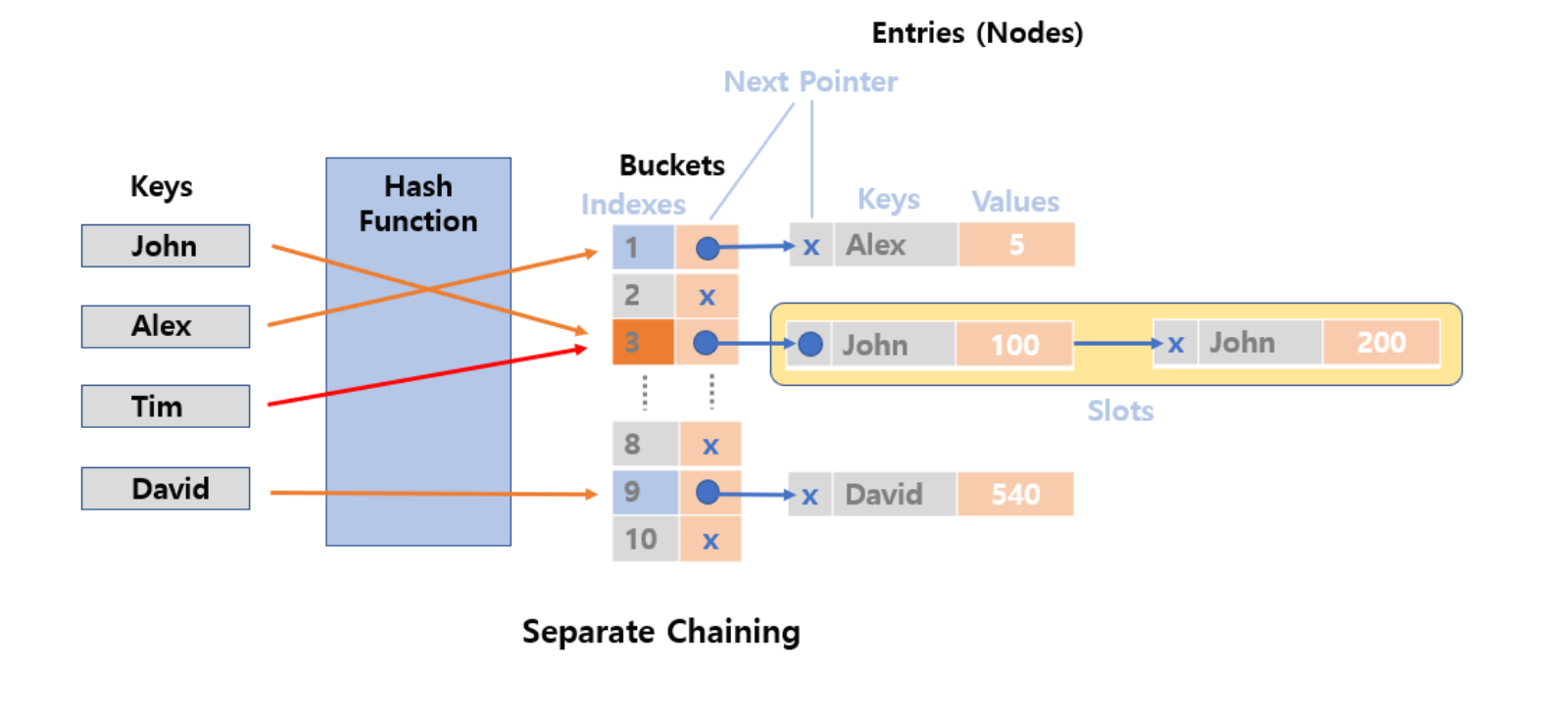
Separate Chaining is one of the methods for resolving collisions in hash tables, which manages data stored in the same bucket by linking them with a linked list.
When accessing the same bucket, it searches for data by following the linked list, as shown in the diagram.
Chaining method has the advantage of not requiring expansion of the hash table, being simple to implement, and being easy to delete data.
However, the disadvantage is that as the number of data increases, the efficiency of the cache decreases as more data is linked to the same bucket with a linked list.
Advantages:
Efficient use of limited buckets. No need to allocate space in advance, reducing memory usage. Use of linked lists reduces constraints on the amount of data that can be added.
Disadvantages:
Reduced search efficiency when multiple keys have the same hash and multiple items are in one bucket. Additional memory is required to use linked lists. In the worst case, all nodes can be inserted into the same bucket.
Time complexity:
Worst case- O(n) A linked list of length n can be created if all keys are hashed to one slot. Average performance: O(1+α) (α = Load factor) It takes O(1) time to access the table slot, and O(α) time to search the list in that slot.
Open Addressing:
Open Addressing is a method that utilizes the empty spaces in a hash table, unlike the Chaining method that uses additional memory such as linked lists. Therefore, it takes up less memory than the Separate Chaining method.
In a hash table, one hash and one value are maintained to match.
When a collision occurs in a bucket, the index is changed, and the hash is stored in a different bucket.
There are three main methods for implementing Open Addressing.
- Linear Probing
When a collision occurs, search for the next available bucket by moving a fixed distance from the current bucket index and store the data in the first available bucket found.
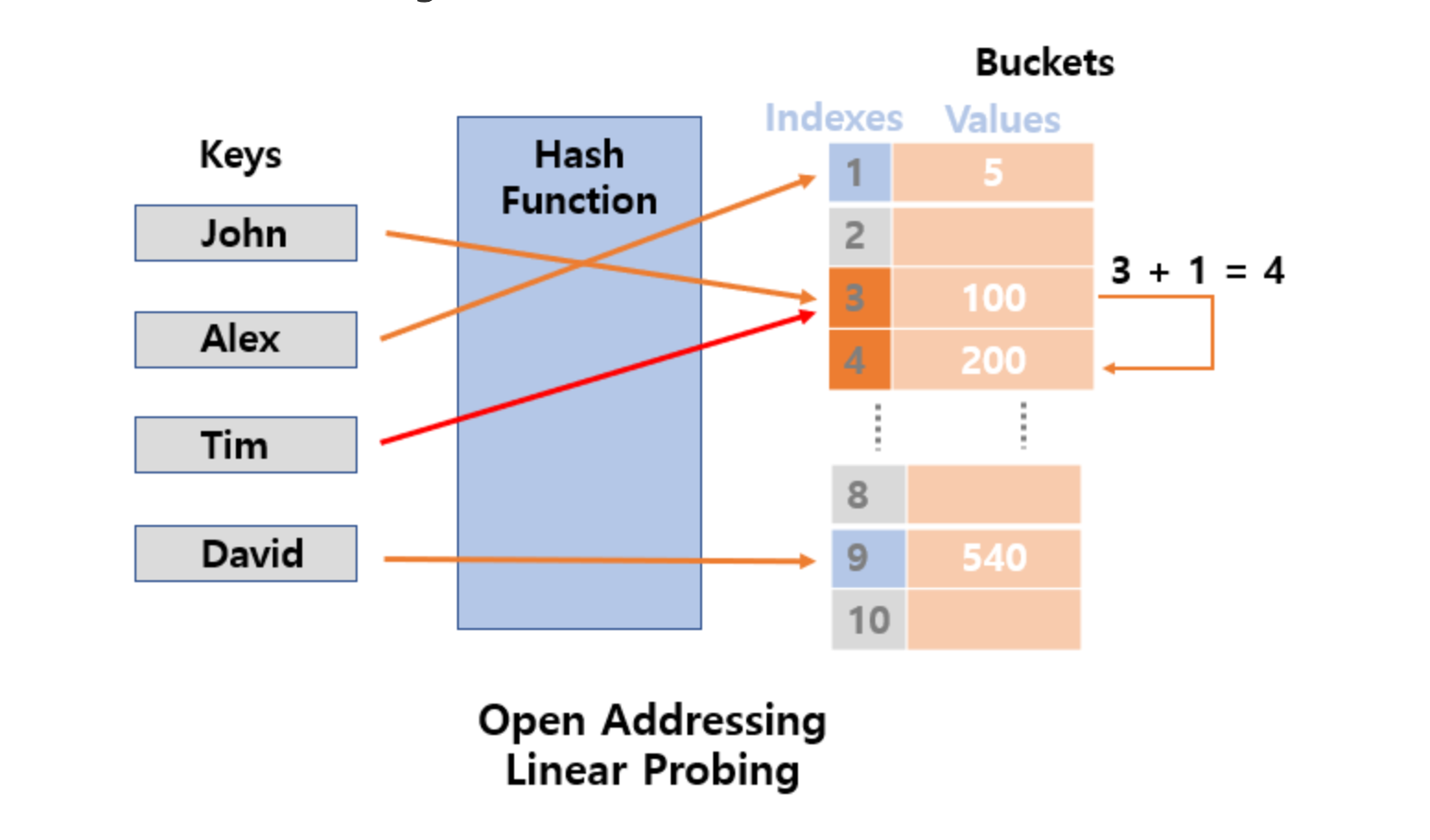
Advantages: Easy to implement.
Disadvantages: Primary clustering problem Clustering is a phenomenon where groups of consecutive data are formed, and it can degrade hashing efficiency by taking longer search time.
The search interval can be set to a value other than 1, but it should be chosen as a prime number that is relatively prime to the table size to reduce the clustering phenomenon.
Also suffers from secondary clustering problem which can occur when a probing sequence hits an already occupied slot, resulting in another probing sequence starting from that position.
2. Quadratic Probing
This method stores the hash sequence widths as squares.
For example, if a
collision occurs for the first time, the data is stored by moving one
position, and if subsequent collisions continue to occur, the data is
stored by moving two, four, and so on positions according to the square
of the sequence number.

Advantages:
- Less clustering than linear probing.
Disadvantages:
- Secondary clustering problem. If the initial probe value of two keys is the same, the process of finding an empty slot will be the same, leading to searching the same slot repeatedly at the next collision position.
3. Double Probing is a method of eliminating the regularity of hashing by hashing the hashed value once more and assigning a new address. Because the hashed value is hashed again to assign a new address, it requires more operations than other methods.
Advantages:
- Less clustering compared to linear probing.
Disadvantages:
- Secondary clustering problem: If the initial probe values of two keys are the same, they will search for the same slot because they follow the same process of finding an empty slot. Therefore, they will continue to collide repeatedly at the same position as they did initially.
- When deleting data in open addressing, the deleted space is utilized as a dummy space, and reorganization of the hash table is required.
- The load factor in open addressing is less than or equal to 1 because the array size is limited.
- The computational complexity in open addressing is proportional to the number of probes, so the time complexity can be represented by the number of search probes.
- For linear probing, the time complexity is as follows: successful search - 1/2 * 1 + 1/(1-α), unsuccessful search - 1/2 * 1 + 1/(1-α)^2. If the load factor exceeds 0.5 in linear probing, the number of unsuccessful searches increases dramatically, so it is necessary to increase the size of the hash table to maintain a load factor of less than 0.5.
- It is recommended to maintain a load factor of less than 0.5 in quadratic probing and double hashing.

-
https://www.geeksforgeeks.org/java-util-hashtable-class-java/
-
https://www.tutorialspoint.com/python_data_structure/python_hash_table.htm