Quick Sort
Quick Sort is a sorting algorithm first proposed by Charles Antony Richard
Hoare in 1960, and since then, many people have modified and improved
it.
Even after more than half a century since its introduction, Quick Sort remains
one of the fastest sorting algorithms in existence.
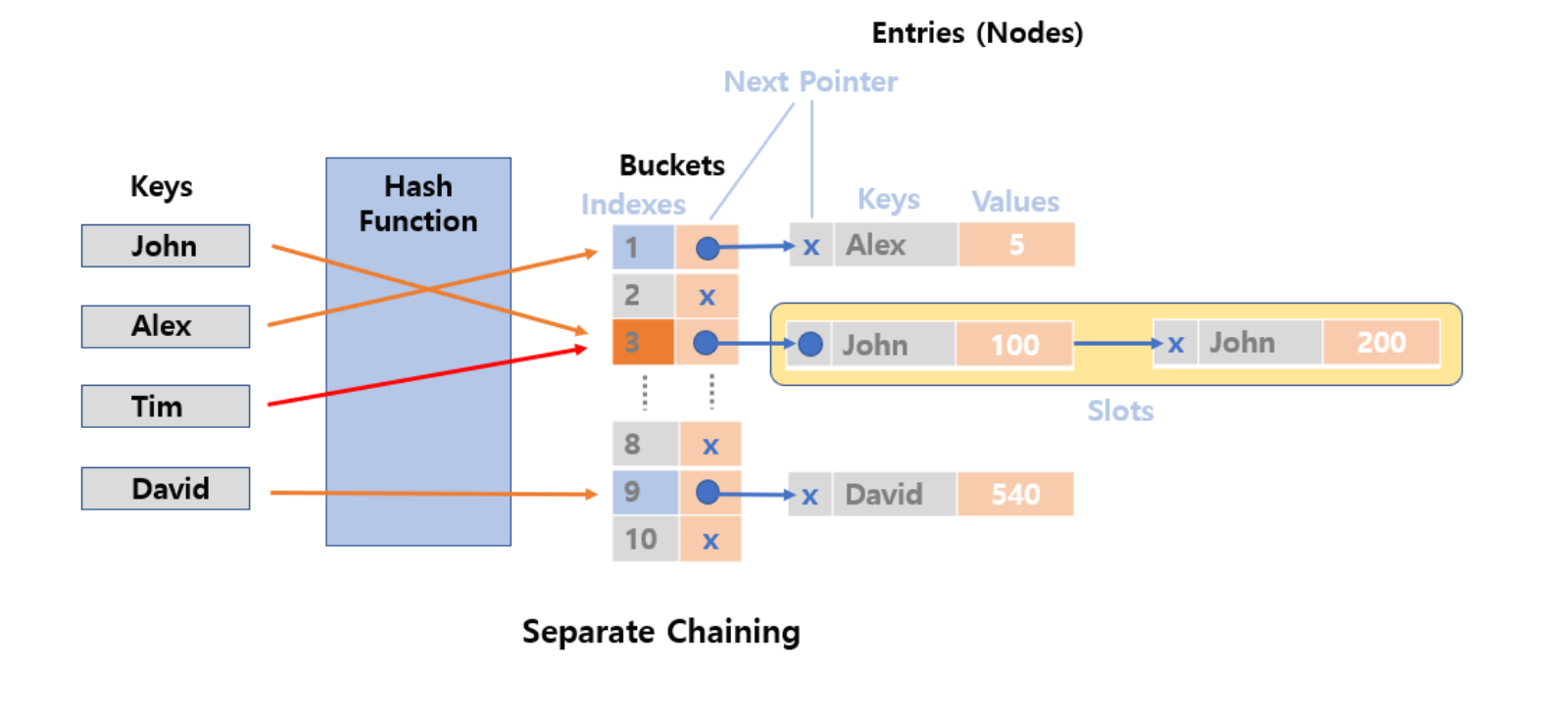
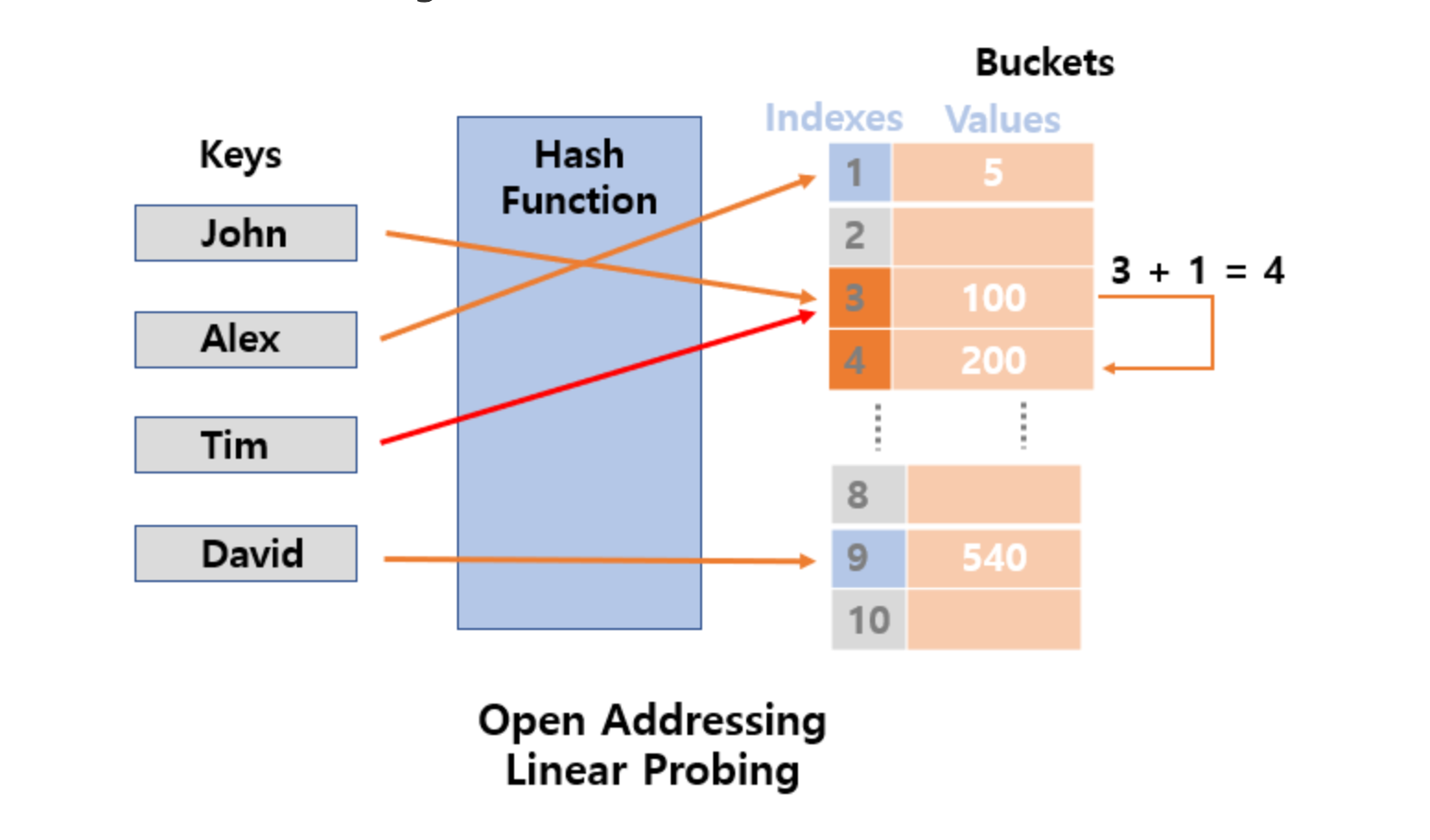
There are two types of Quick Sort: in-place and not in-place.
The in-place method, which uses less memory, is the most commonly used.
However, the not in-place method is easier to understand intuitively, so we
will explain that first, followed by the in-place method
graphical representation:

-
Choose a pivot element. In this example, we've chosen the first element of
the array as the pivot.
-
Partition the array into two sub-arrays: one containing elements smaller
than the pivot, and one containing elements greater than the pivot.
- Recursively apply the quicksort algorithm to the sub-arrays.
The above method of quicksort is not an in-place method and requires
additional memory space. Therefore, it may not be a practical solution for
sorting large datasets due to the potential for significant memory waste.
However, using this method, we can achieve a stable sort where the order of
duplicate elements remains unchanged since duplicate elements are sequentially
placed on the pivot element during the sorting process.
Merge Sort:
Merge sort is a stable sorting algorithm that belongs to the category of
divide and conquer algorithms, which was proposed by John von Neumann.
Divide and conquer is a problem-solving strategy that involves dividing a
problem into smaller sub-problems, solving each sub-problem, and combining the
solutions to solve the original problem.
The divide and conquer approach is often implemented using recursive function
calls.
The merge sort algorithm works by dividing an unsorted list into
two equal-sized sublists, sorting each sublist recursively using merge sort,
and then merging the sorted sublists to create a sorted list.

The merge sort algorithm involves the following steps: Divide the input array
into two equal-sized subarrays; Sort each subarray recursively using merge sort;
Merge the two sorted subarrays to create a single sorted array.
Merge sort requires additional memory for merging the subarrays, but it
provides a stable sort and guarantees a worst-case time complexity of O(n log
n).
Quick Sort:
-
Sorts an array by dividing it into two sub-arrays based on the pivot
value.
-
If the size of the sub-array is small enough, it is sorted directly.
Otherwise, the process is repeated recursively.
-
The position of each pivot is guaranteed to be fixed after each sort,
ensuring that the sorting process will eventually end.
- The choice of pivot can be optimized to improve the efficiency.
Merge Sort:
-
Sorts an array by dividing it into two sub-arrays, sorting them
recursively if necessary, and then merging them into one list.
-
Merge sort is a stable sorting algorithm, while Quick Sort is not.
-
The time complexity of both algorithms is O(n log n), but the worst
case time complexity of Quick Sort is O(n^2).
-
Merge Sort requires additional memory space for the merging process.
Common features:
- Both algorithms are based on the divide and conquer strategy.
-
Both algorithms are generally faster than other sorting algorithms.